😃 Hi!
I am Yujie Wei (卫昱杰), a fourth-year Ph.D. student at Fudan University, advised by Prof. Hongming Shan. I received my Bachelor’s degree in Software Engineering from Sichuan University, advised by Prof. Yi Zhang.
My research interests include 2D/3D Generative Models and Representation Learning, with a particular focus on:
-
Video and Image Generation (specifically on Customization and Controllable Generation)
-
Foundation Model Architecture
-
Self-Supervised Learning
🔥 News
- 2026.02: 🎉 CineNeuron🚀, SynMotion are accepted by CVPR 2026. Honored to collaborate with them on these promising projects.
- 2026.01: 🎉 ProMoE🚀 is accepted by ICLR 2026.
- 2025.09: 🎉 RepLDM, TTS-VAR are accepted by NeurIPS 2025. Honored to collaborate with them on these promising projects.
- 2025.06: 🎉 DreamRelation🚀, FreeScale, PersonalVideo are accepted by ICCV 2025. Honored to collaborate with them on these promising projects.
- 2025.03: 🎉 TeaCache is accepted by CVPR 2025 Highlight. Congrats to Feng.
- 2024.09: 🎉 EvolveDirector is accepted by NeurIPS 2024. Congrats to Rui.
- 2024.02: 🎉 DreamVideo🚀, InstructVideo, HiGen are accepted by CVPR 2024. Honored to collaborate with them on these promising projects.
- 2023.08: 🎉 Emo-DNA is accepted by ACM MM 2023. Congrats to Jiaxin.
- 2023.07: 🎉 OnPro🚀 is accepted by ICCV 2023.
- 2023.02: 🎉 Temporal Modeling Matters is accepted by ICASSP 2023. Congrats to Jiaxin.
📝 Publications
Selected Publications
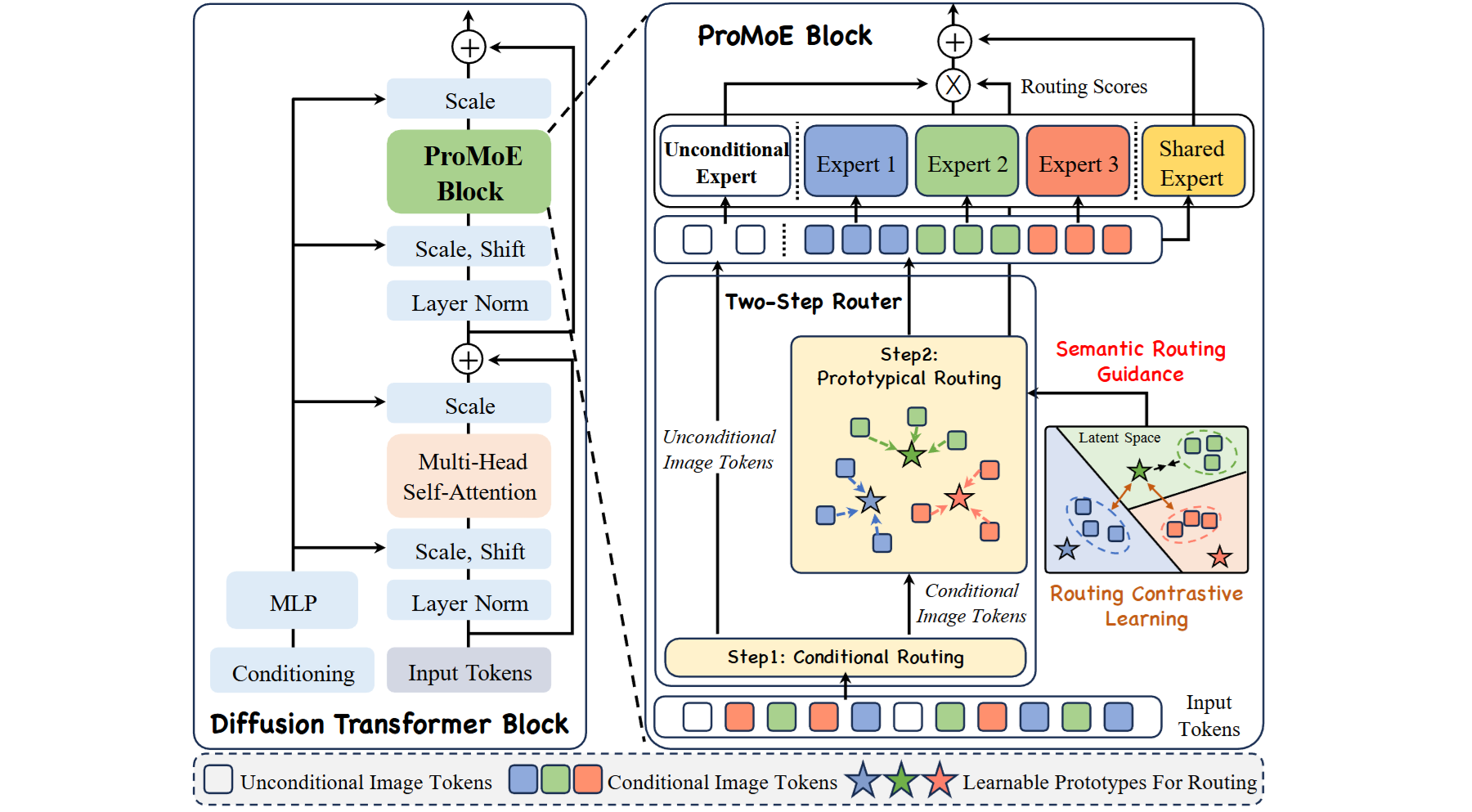
[Model Architecture] Routing Matters in MoE: Scaling Diffusion Transformers with Explicit Routing Guidance
Yujie Wei, Shiwei Zhang, Hangjie Yuan, Yujin Han, Zhekai Chen, Jiayu Wang, Difan Zou, Xihui Liu, Yingya Zhang, Yu Liu, Hongming Shan
- ProMoE is an MoE framework featuring a two-step router with explicit routing guidance that promotes expert specialization.

[Video Generation] DreamRelation: Relation-Centric Video Customization
Yujie Wei, Shiwei Zhang, Hangjie Yuan, Biao Gong, Longxiang Tang, Xiang Wang, Haonan Qiu, Hengjia Li, Shuai Tan, Yingya Zhang, Hongming Shan
- DreamRelation is the first relational video customization method that personalizes user-specified relations.

[Video Generation] DreamVideo: Composing Your Dream Videos with Customized Subject and Motion
Yujie Wei, Shiwei Zhang, Zhiwu Qing, Hangjie Yuan, Zhiheng Liu, Yu Liu, Yingya Zhang, Jingren Zhou, Hongming Shan


- DreamVideo is the first method that generates customized videos from a few static images of the desired subject and a few videos of target motion.
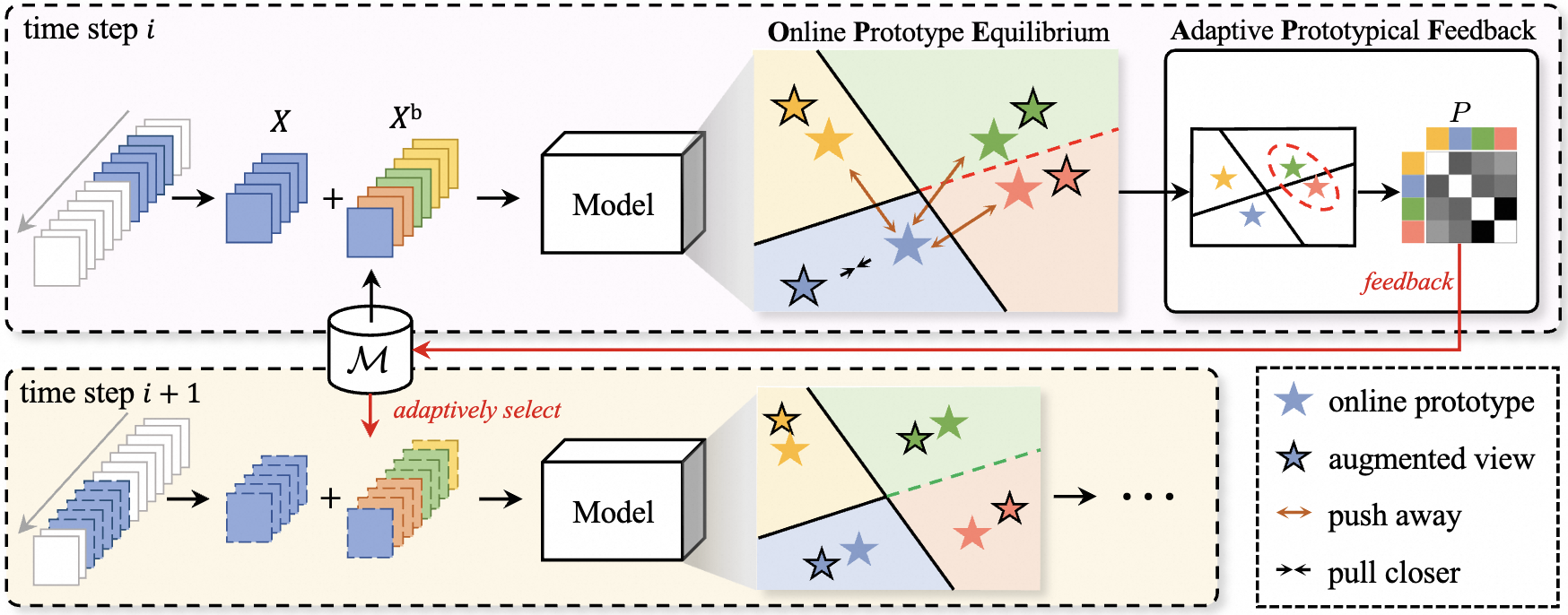
[Continual Learning] Online Prototype Learning for Online Continual Learning
Yujie Wei, Jiaxin Ye, Zhizhong Huang, Junping Zhang, Hongming Shan
- OnPro is the first work to identify shortcut learning as the key limiting factor for online continual learning, offering new insights into why online learning models fail to generalize well.

[Video Generation] DreamVideo-Omni: Omni-Motion Controlled Multi-Subject Video Customization with Latent Identity Reinforcement Learning
Yujie Wei, Xinyu Liu, Shiwei Zhang, Hangjie Yuan, Jinbo Xing, Zhekai Chen, Xiang Wang, Haonan Qiu, Rui Zhao, Yutong Feng, Ruihang Chu, Yingya Zhang, Yike Guo, Xihui Liu, Hongming Shan
- DreamVideo-Omni is a unified framework enabling harmonious multi-subject customization with omni-motion control via omni-motion and identity supervised finetuning as well as latent identity reward feedback learning.
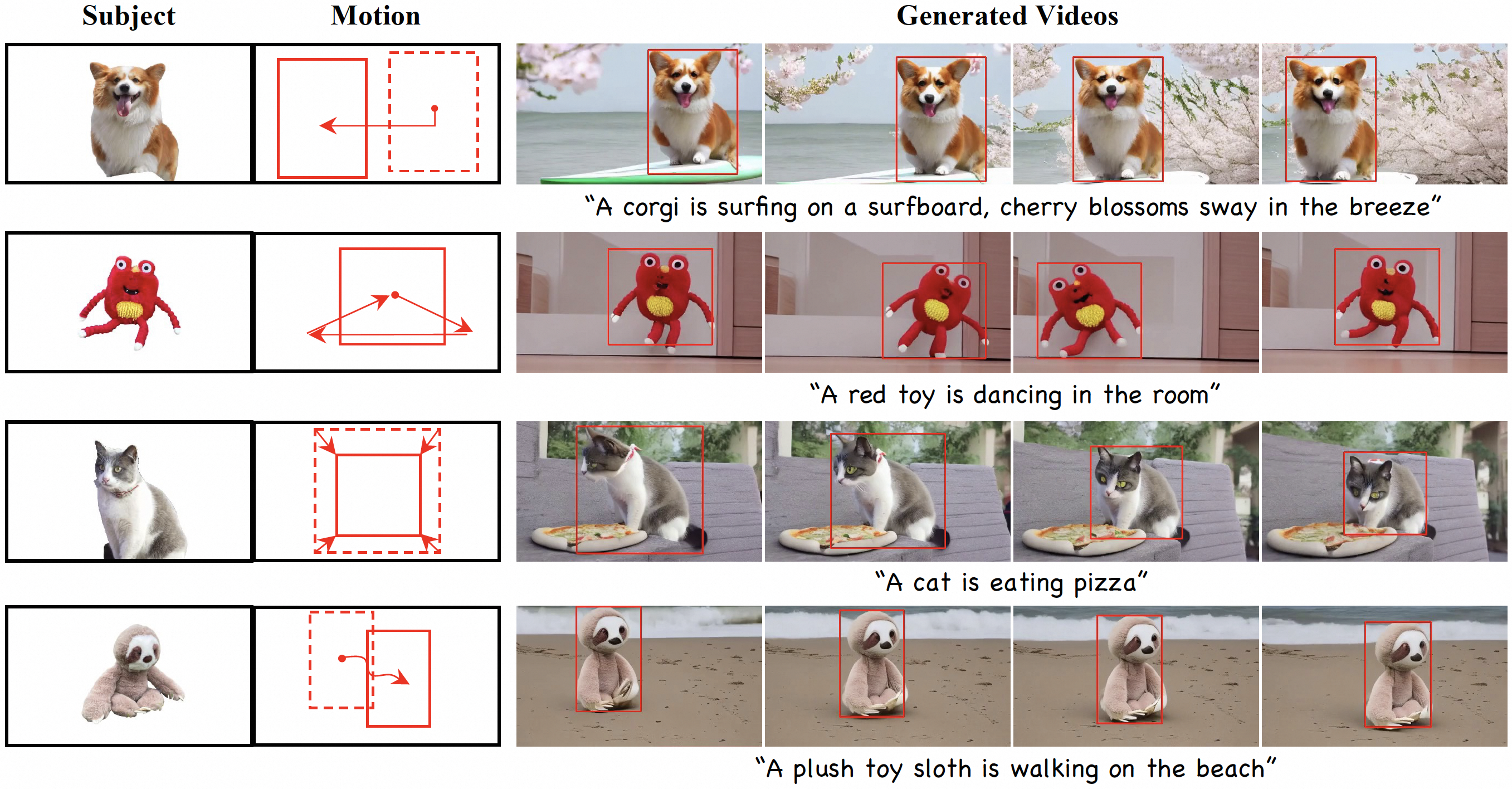
[Video Generation] DreamVideo-2: Zero-Shot Subject-Driven Video Customization with Precise Motion Control
Yujie Wei, Shiwei Zhang, Hangjie Yuan, Xiang Wang, Haonan Qiu, Rui Zhao, Yutong Feng, Feng Liu, Zhizhong Huang, Jiaxin Ye, Yingya Zhang, Hongming Shan
- DreamVideo-2 is the first zero-shot (tuning-free) framework that generates customized videos with specified subjects and motion trajectories.
Collaborative Publications

FreeScale: Unleashing the Resolution of Diffusion Models via Tuning-Free Scale Fusion
Haonan Qiu, Shiwei Zhang, Yujie Wei, Ruihang Chu, Hangjie Yuan, Xiang Wang, Yingya Zhang, Ziwei Liu
- FreeScale proposes a tuning-free inference paradigm to enable higher-resolution visual generation via scale fusion.
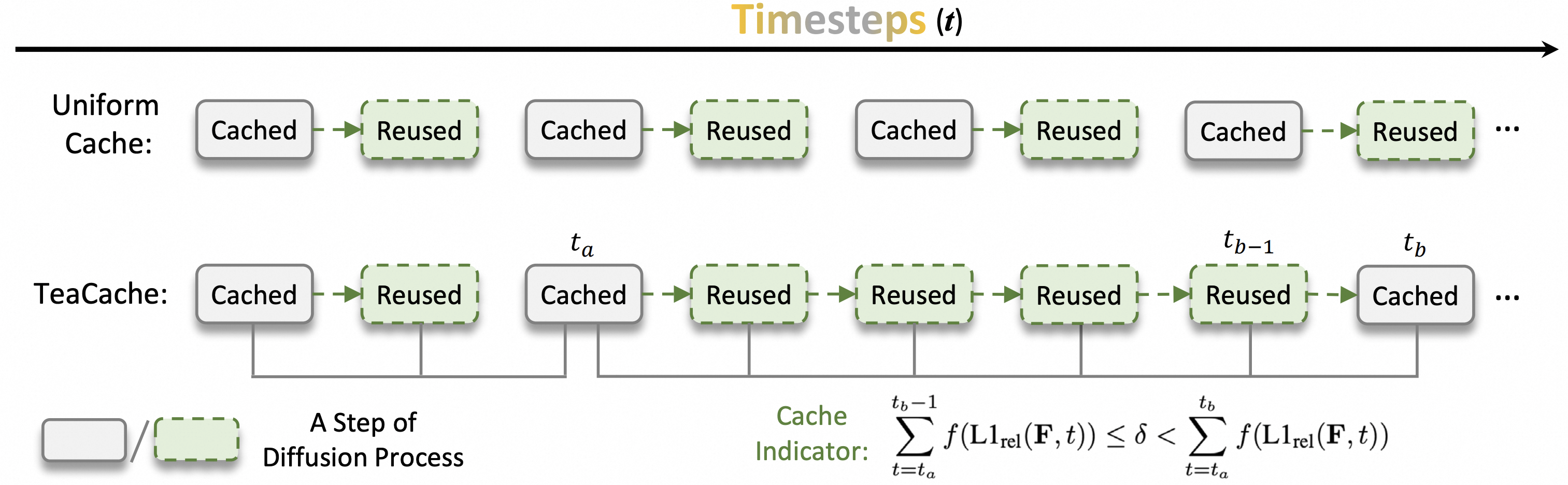
Timestep Embedding Tells: It’s Time to Cache for Video Diffusion Model
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, Fang Wan
- TeaCache is a training-free caching approach that estimates and leverages the fluctuating differences among model outputs across timesteps.

EvolveDirector: Approaching Advanced Text-to-Image Generation with Large Vision-Language Models
Rui Zhao, Hangjie Yuan, Yujie Wei, Shiwei Zhang, Yuchao Gu, Lingmin Ran, Xiang Wang, Zhangjie Wu, Junhao Zhang, Yingya Zhang, Mike Zheng Shou
- EvolveDirector explores the feasibility of training a text-to-image generation model comparable to advanced models using publicly available resources.
InstructVideo: Instructing Video Diffusion Models with Human Feedback
Hangjie Yuan, Shiwei Zhang, Xiang Wang, Yujie Wei, Tao Feng, Yining Pan, Yingya Zhang, Ziwei Liu, Samuel Albanie, Dong Ni
- InstructVideo is the first research attempt that instructs video diffusion models with human feedback.

Hierarchical Spatio-Temporal Decoupling for Text-to-Video Generation
Zhiwu Qing, Shiwei Zhang, Jiayu Wang, Xiang Wang, Yujie Wei, Yingya Zhang, Changxin Gao, Nong Sang
- HiGen is a method that improves T2V performance by decoupling the spatial and temporal factors from the structure and content level.
-
CVPR 2026SynMotion: Semantic-Visual Adaptation for Motion Customized Video Generation, Shuai Tan, Biao Gong, Yujie Wei, Shiwei Zhang, Zhuoxin Liu, Dandan Zheng, Jingdong Chen, Yan Wang, Hao Ouyang, Kecheng Zheng, Yujun Shen. -
NeurIPS 2025 SpotlightRepLDM: Reprogramming Pretrained Latent Diffusion Models for High-Quality, High-Efficiency, High-Resolution Image Generation, Boyuan Cao, Jiaxin Ye, Yujie Wei, Hongming Shan. -
NeurIPS 2025TTS-VAR: A Test-Time Scaling Framework for Visual Auto-Regressive Generation, Zhekai Chen, Ruihang Chu, Yukang Chen, Shiwei Zhang, Yujie Wei, Yingya Zhang, Xihui Liu. -
ICCV 2025PersonalVideo: High ID-Fidelity Video Customization without Dynamic and Semantic Degradation, Hengjia Li, Haonan Qiu, Shiwei Zhang, Xiang Wang, Yujie Wei, Zekun Li, Yingya Zhang, Boxi Wu, Deng Cai. -
ACM MM 2023Emo-DNA: Emotion Decoupling and Alignment Learning for Cross-Corpus Speech Emotion Recognition, Jiaxin Ye, Yujie Wei, Xin-Cheng Wen, Chenglong Ma, Zhizhong Huang, Kunhong Liu, Hongming Shan. -
ICASSP 2023Temporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition, Jiaxin Ye, Xin-Cheng Wen, Yujie Wei, Yong Xu, Kunhong Liu, Hongming Shan.
🎖 Honors and Awards
- 2026.03 ICLR2026 Financial Assistance (Maximum Funding)
- 2025.09 ICCV2025 Broadening Participation Award
- 2022.05 Outstanding Graduates of Sichuan Province and Sichuan University
- 2021.10 National Scholarship (Top 1%)
- 2020.10 The First Prize Scholarship (Top 3%)
- 2020.05 Sichuan University Top 100 Student Leaders
- 2019.10 National Scholarship (Top 1%)
🎓 Academic Service
- Conference Reviewer: ICLR, CVPR, ICCV, ACM MM, NeurIPS, SIGGRAPH Asia, ICML, BMVC, ECCV.
- Journal Reviewer: TPAMI (Certificate), TIP, Information Fusion.
{kind=link}
💬 Invited Talks
📖 Educations
- 2022.09 - 2027.06 (now), Ph.D., Fudan University, Shanghai, China.
- 2018.09 - 2022.06, Bachelor of Software Engineering, Sichuan Univeristy, Chengdu, China.